What is covered?
- Types of optimizers and learning rates
- Keras callbacks and checkpoints like early stopping, adjusting learning rates, etc.
Types of optimizers and adaptive learning methods
Optimizers
In neural networks an optimizer serve as the necessary aid with the algorithm to minimize the loss during the training process. For example: Gradient Descent, Stochastic Gradient Descent, Mini Batch Gradient Descent, etc. (more details can be found here)
In Keras following are the most widely used optimizers that can easily be integrated with any neural network:
- SGD
- Adam
- RMSprop
- AdaGrad
- AdaDelta
- Adamax
- Nadam
Since, Keras is now integrated in Tensorflow itself, we can directly use these optimizers using tensorflow version greater than 2.0 (here)
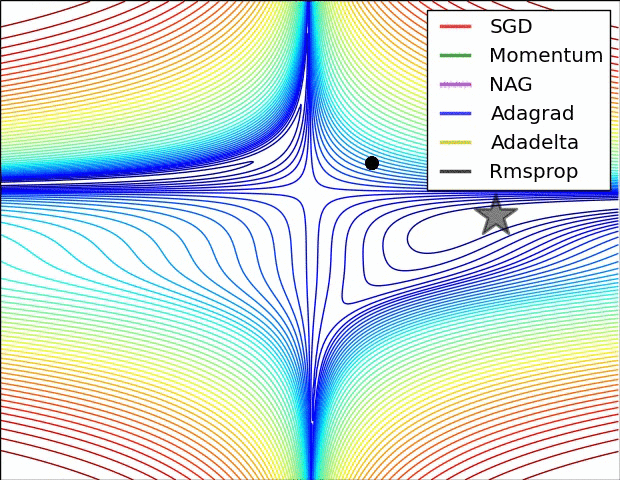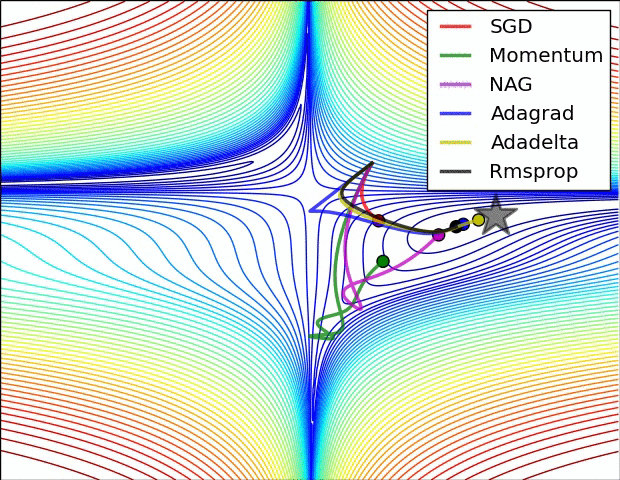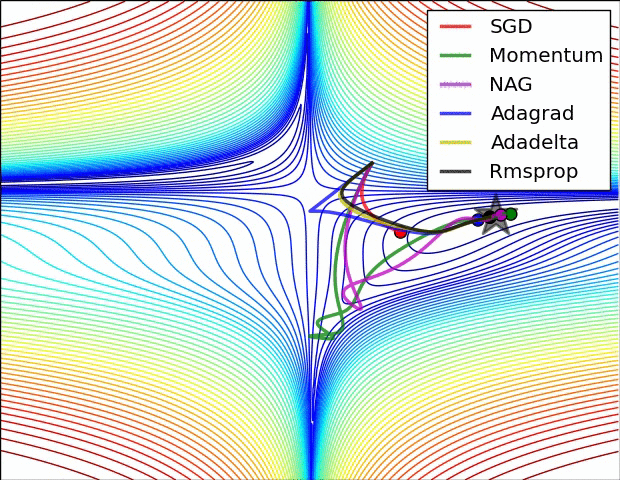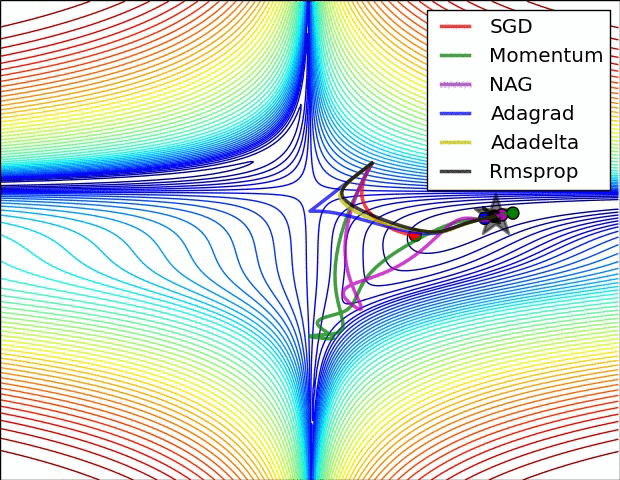
The illustration in Fig. 1 shows how adaptive learning algorithm converges to global minima, where Adadelta appears to be faster, however in practice I find Adam as best optimizer. (the results may vary depending on the problem under consideration, hence one optimizer may be bad in one problem but may be good in another). These optimizers are implemented over a toy example here (can be utilized for better understanding or proposing something new).
Constant learning rates are bad!
Consider a situation where after very large epochs we think that we are close to convergence, but the problem occurs, where training and test loss stops improving and the gradients just fluctuate around global minima due to constant learning rate. So the idea is to keep the learning rate as small as possible, however keeping small learning rate will take forever to train the model. Hence, follows the idea of adaptive learning rate.
The aforementioned learning rate optimizers offer adaptive optimization of the learning rate for better training. The main difference in these algorithms is how they manipulate the learning rate to allow for faster convergence and better validation accuracy. Some require manual setting of parameters or heuristic approach to adjust the learning rates (hyperparameters).
Keras callbacks and checkpoints
- Checkpoint models: This is a simple but very useful way of saving your best model before it starts overfitting. This allows to keep saving weights / models after each epoch. Moreover, Keras has the ability to save only the best model by monitoring the validation loss (or any other metric).
- EaryStopping: It is another Keras callback that allows to stop training once the value being monitored (e.g. val_loss) has stopped getting better (decreasing). This requires to set a ‘patience’ parameter to wait and monitor for some amount of epochs before stopping.
- TensorBoard: This is a very useful callback which helps to monitor each metric by visualization (graphical and contour plots). This can be used to real-time (live) visualize the change in the performance of model during training. Furthermore, it can also be used to visualize the complex structures of the neural network and variation in other parameters while training. To view the training progress you can use following command in the cmd (logs/fit is a path of tensorboard logs):
tensorboard --logdir logs/fit- CSVLogger: It is also very useful callback function that helps to keep track of metric values for each epoch. After training is finished it saves a .csv file that contains row wise details of training and validation metrics over each epoch.
To create callbacks we can proceed as follows:
from tensorflow.keras.callbacks import ModelCheckpoint, TensorBoard, CSVLogger, EarlyStopping
import datetime
# Some other code #
cur_date = datetime.datetime.now().strftime("%Y%m%d-%H%M%S")
tensorboard_callback = TensorBoard(log_dir=logs/fit/, histogram_freq=0)
model_checkpoint = ModelCheckpoint('model.hdf5', monitor='loss', verbose=1, save_best_only=True)
early_stopping = EarlyStopping(monitor='loss', verbose=1, patience=8)
csv_logger = CSVLogger(logs/cur_date + '.log', separator=',', append=False)
callbacks = [tensorboard_callback, model_checkpoint, early_stopping, csv_logger]
# During fit command we can pass these callbacks #
m.fit(x=X_train,
y=Y_train,
batch_size=train_batch_size,
epochs=epochs,
verbose=1,
callbacks=callbacks,
validation_split=val_split)