Publication details
The paper is published in the journal of Springer Machine Vision and Applications in 2022: click here
Abstract
To automate the process of delineation to highlight or identify the tumor regions in breast ultrasound imaging. This paper introduces cross spatial attention filters in the residual inception U-Net model (based on our previous work on the IU-Net model, here ) to effectively draw the attention of the network towards tumor structures. The performance of the model is validated over BUSI and BUSIS datasets.
Highlights
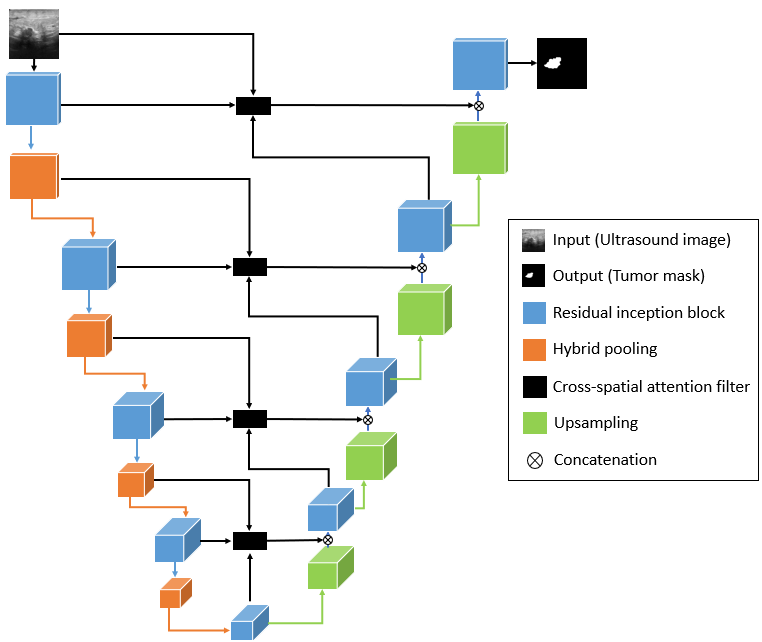
- A novel architecture, residual cross-spatial attention guided inception U-Net model (RCA-IUnet) is introduced with long and short skip connections to generate binary segmentation mask of tumor using ultrasound imaging.
- Instead of the direct concatenation of encoder feature maps with upsampled decoded feature maps, a cross-spatial attention filter is introduced in the long skip connections that use multi-level encoded feature maps to generate attention maps for concatenation with decoded feature maps.
- Hybrid pooling operation is introduced that uses a combination of spectral and max pooling for efficient pooling of the feature maps. It is utilized in two modes: a) same: used in inside inception block b) valid: used to connect inception blocks (reduce the spatial resolution by half the input feature map).
- The model is also equipped with short skip connections (residual connections) along with the inception depth-wise separable convolution layers (concatenated feature maps from 1×1, 3×3, 5×5 and hybrid pooling).
- The source code is available on my GitHub page here.
Overview
The schematic representation of the proposed model is shown in Fig. 1. Similar to the IU-Net model, this network also follows U-Net topology with residual inception convolution blocks and hybrid pooling for downsampling. Additionally, it uses cross spatial attention filters in the skip connections to propagate relevant spatial features from encoder to decoder block.
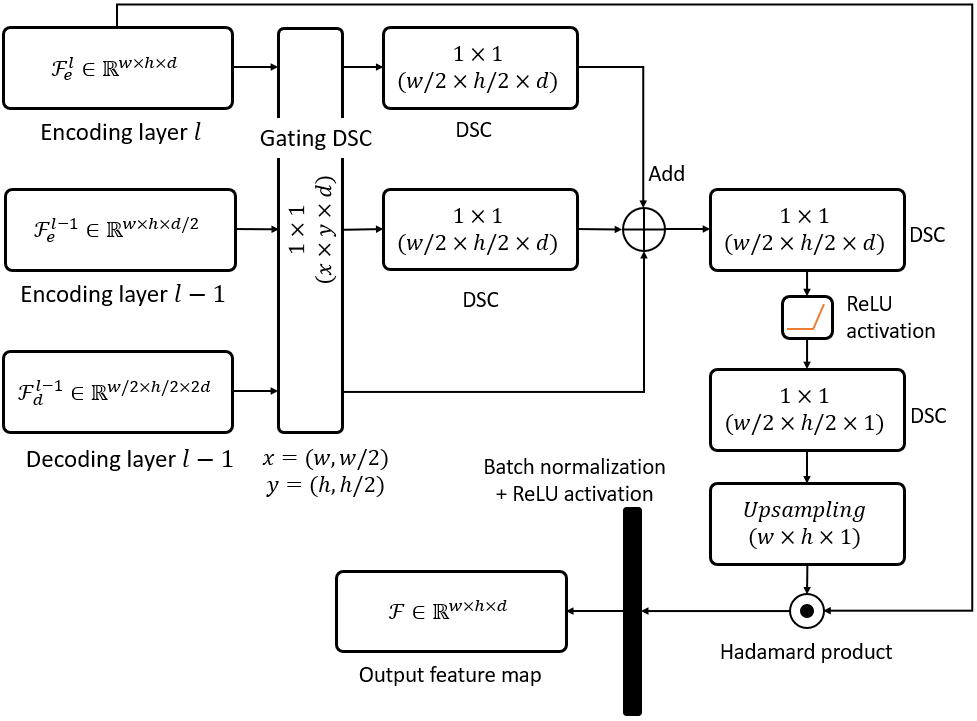
The schematic representation of the cross-spatial attention approach is illustrated in Fig. 2, where feature maps from three different layers are considered,  ,
,  and
and  . Each of these feature maps passes through gating DSC to make the depth of each feature map compatible for fusion. Later, the gated feature maps
. Each of these feature maps passes through gating DSC to make the depth of each feature map compatible for fusion. Later, the gated feature maps  and
and  are downsampled with strided DSC. Then fused feature map is generated by merging these feature maps using addition. The spatial attention descriptor is formed by performing another 1×1 DSC with ReLU activation followed by depth contraction with single 1×1 DSC filter and upsampling. The spatial attention descriptor then undergoes element-wise multiplication with input feature map followed by batch normalization and ReLU activation to generate cross spatial attention map.
are downsampled with strided DSC. Then fused feature map is generated by merging these feature maps using addition. The spatial attention descriptor is formed by performing another 1×1 DSC with ReLU activation followed by depth contraction with single 1×1 DSC filter and upsampling. The spatial attention descriptor then undergoes element-wise multiplication with input feature map followed by batch normalization and ReLU activation to generate cross spatial attention map.
Output
Below Fig. 3 shows the segmentation results of the different segmentation models.

Findings
With exhaustive trials, the proposed model achieved significant improvement over the state-of-the-art models with minimal training parameters on two publicly available datasets. Furthermore, the minimal impact of post-processing on the segmentation performance of the model indicates that the model produces least number of false predictions.
For more details please refer to my paper here.