Publication Details
The paper is published in the International Conference on Big Data Analytics 2018. For more details: click here
Highlights
- A novel concept drift detection algorithm is proposed.
- Achieved significant improvements over the prediction results after applying concept drift detection in the classification model.
Introduction
Data stream is a continuous flow of data arriving at very high speed. The acquired information can be utilized for training deep learning or machine learning model to fit our desired purpose. In this work, we tend to identify the concept drift in the data stream using data mining approach before it is fed to classification model.
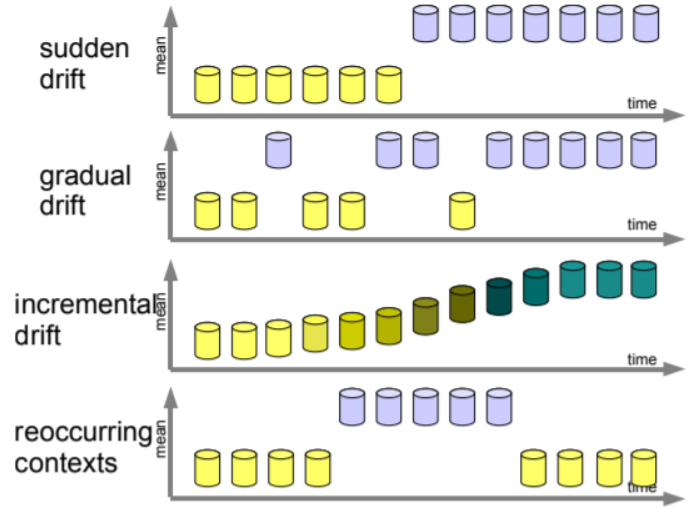
Concept drift is one major challenge in the data stream analytics that needs to be tackled for any application or task. It is defined as the change in the properties of the data in such a way that it changes the prediction behavior of the classification model. It can occur in sudden, gradual, incremental or reoccurring manner (as shown in Fig.1).
Aim: Performance analysis/testing of the classification model with and without the proposed concept drift detection technique.
Concept Drift Detection
Approach: Initially start by building the classification model in the training phase. Before predicting the unlabeled data, it is passed through concept drift detection procedure and check how it relates to the current behavior of the model.
Procedure:
- Find the centroids of all the available classes.
- Compute the distance vector of the test instance (unknown sample) from the centroid of the classes.
- Calculate count (
 ) of data points which are in vicinity of test instance of a particular class (
) of data points which are in vicinity of test instance of a particular class ( ).
). - Then the ratio of the count () and total data points (
 ) of the class () gives the value of the parameter ‘
) of the class () gives the value of the parameter ‘ ‘, i.e.
‘, i.e.  .
. - Find this parameter ‘‘ for each class.
- Smaller the value of ‘‘ greater is the chance that it belongs to that class.
- Now define some threshold ‘
 ‘ for sensitivity of detection mechanism. Smaller the threshold value the more is the sensitivity to detect the concept drift.
‘ for sensitivity of detection mechanism. Smaller the threshold value the more is the sensitivity to detect the concept drift. - If all the values of ‘‘ corresponding to test data points with respect to all the classes are greater than the threshold then it can be concluded that it would lead to concept drift in the model
Results
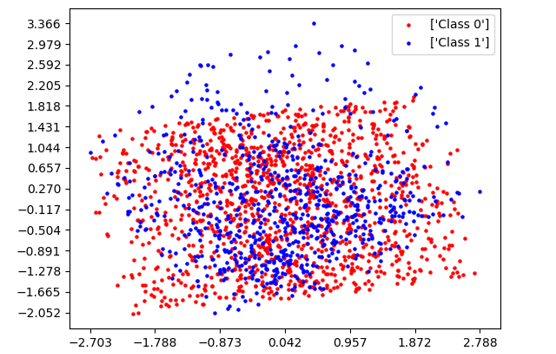
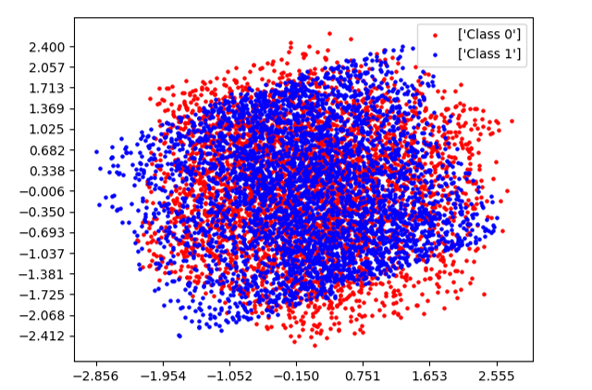
SEA Dataset:
- Artificial dataset.
- Three features ranging from 0 to 10.
- Two classes which are categorized as 0 or 1.
- Number of samples: 2500.
- 2-D representation is shown in Fig. 2(a) using Principal Component Analysis (PCA).
- The average accuracy of the model is shown in below table.
| Prediction Approach | Threshold | ||
| 0.7 | 0.4 | 0.2 | |
| With CD Detection | 82.01% | 84.32% | 98.13% |
| Without CD Detection | 82.01% | 82.10% | 82.28% |
Hyperplane Dataset:
- Artificial dataset.
- Ten features ranging between 0 and 1.
- Two classes which are categorized as 0 or 1.
- Number of samples: 10000.
- 2-D representation is shown using PCA in Fig. 2(b).
| Prediction Approach | Threshold | ||
| 0.7 | 0.4 | 0.2 | |
| With CD Detection | 90.25% | 90.71% | 100.0% |
| Without CD Detection | 90.25% | 90.54% | 90.55% |
Conclusion
- The proposed approach when integrated with the trained classification model tend to improve the prediction accuracy of the model.
- Further improvements can be done to make buffer for detected samples and create novel class.
- Real time concept drift detection is still a challenging task thus opens the opportunity to fill the void of research gaps.
The source code is available at my GitHub page here.